Snowflake is a cloud-based data warehouse that offers a variety of features and capabilities that make it a popular choice for businesses of all sizes. It can be used to store and analyze data from a variety of sources, and it can be easily scaled up or down.
Recently, a team of BBI engineers documented processes for three common small Snowflake projects, actively looking for pitfalls so our clients don’t hit them. This also provided hands-on training for our team members, a staple of our learning-focused culture. In this post, we offer a quick look at each project.
Project 1: Building an automated data pipeline
Use Case
S3 bucket is a common data source used across organizations. Automating the loading of data from S3 into Snowflake saves teams time and energy, while reducing the chance for errors.
Overview
Building automated data pipelines requires extracting data from one or more sources, transforming it into a format that can be loaded into Snowflake, and then loading it into Snowflake.
To build an automated data pipeline for Snowflake, you will need to use a tool such as Airflow or Prefect. These tools allow you to define and schedule data pipelines in a declarative way.
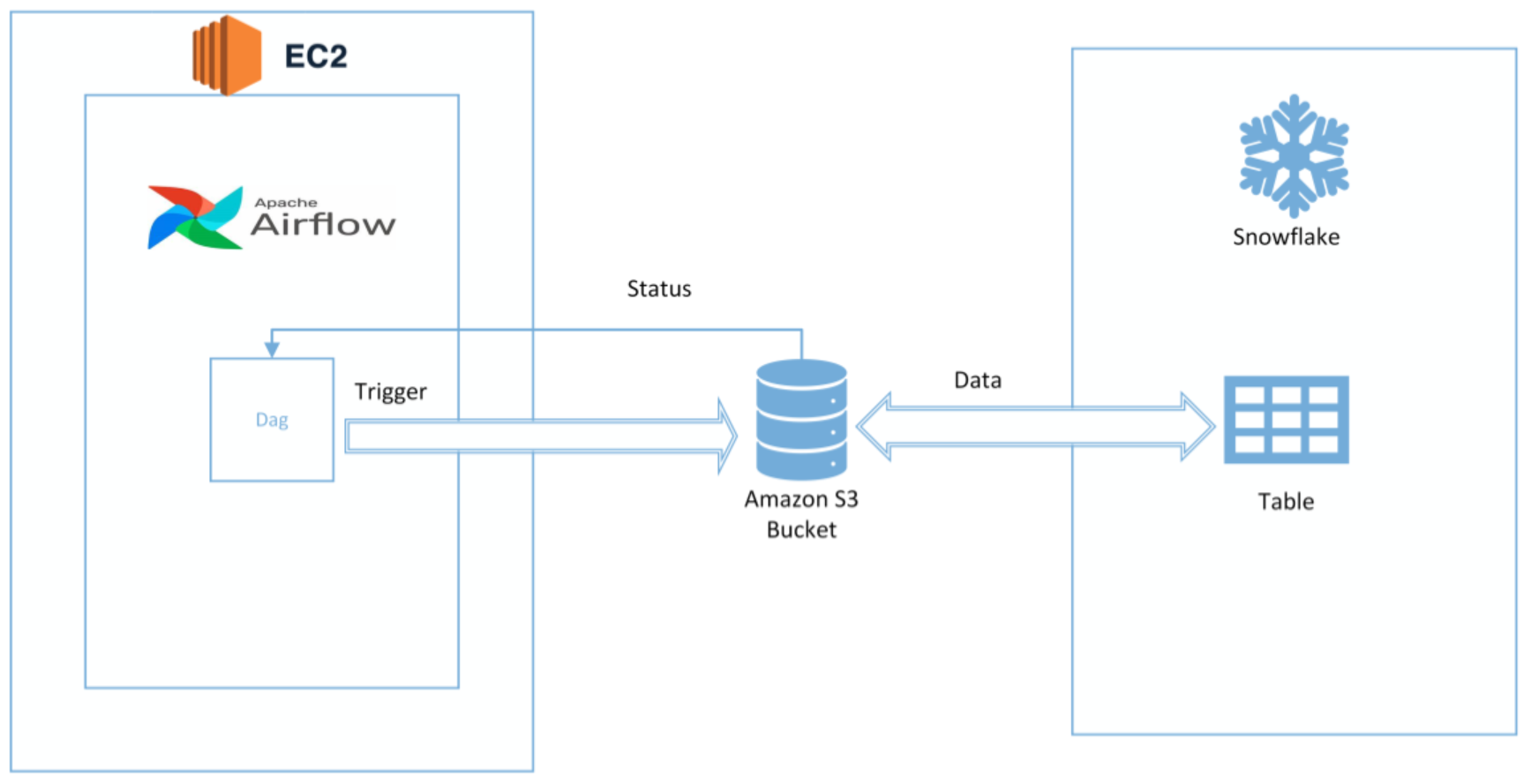
Once you have defined your data pipeline, you can use it to extract data from your sources, transform it, and load it into Snowflake on a regular basis.
Project 2: Loading data from Kafka into Snowflake
Use Case
The more quickly your data moves in your organization, the more quickly you can make thoughtful decisions. Kafka is an open-source streaming platform used to collect and process real-time data. By loading real-time data from a Kafka topic to Snowflake with the Kafka Connector, you’re able to increase speed without sacrificing data quality.
Overview
The Snowflake Connector is a simple and efficient way to load data into Snowflake. To use the Connector, you will need to create a Kafka topic and a Snowflake table. You will then need to configure the connector to connect to your Kafka cluster and your Snowflake account.
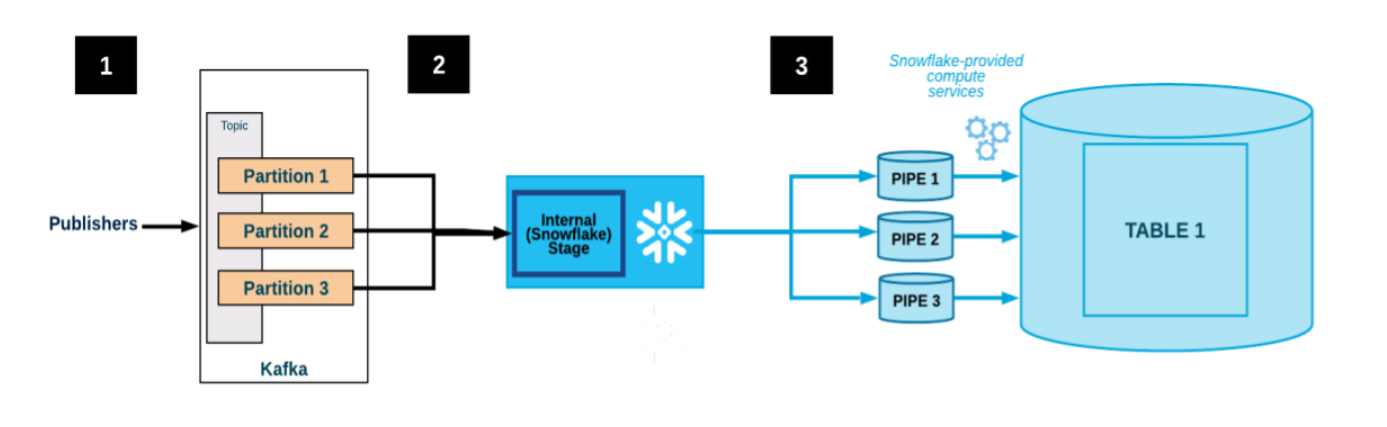
Once the connector is configured, you can start loading data from Kafka into Snowflake. The connector will automatically detect new data in Kafka and load it into the Snowflake table.
Project 3: Integrating Snowflake and Streamlit
Use Case
Streamlit is a popular open-source Python library that can be used to create web-based data applications. When using Streamlit in Snowflake, developers can securely build, deploy, and share apps on Snowflake’s data cloud. This means the data can be processed and used in Snowflake, without having to move code to an external system. You’re able to efficiently visualize and analyze data in one place.
Overview
To integrate Snowflake and Streamlit, you will need to install the Snowflake Streamlit connector. This connector provides a simple and efficient way to connect Streamlit to Snowflake.
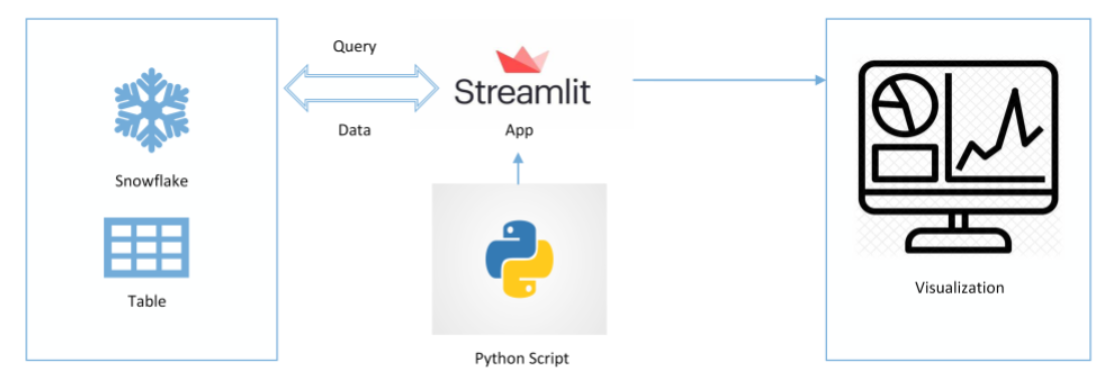
Once the connector is installed, you can start creating data applications in Streamlit. To do this, you will need to import the connector and then connect to your Snowflake account.
Once you are connected to Snowflake, you can start querying data from Snowflake and displaying it in your Streamlit application.
Tips for Implementing Snowflake
If you’re new to Snowflake, here are a couple general tips for getting started.
- Use data governance best practices. It is important to implement data governance best practices when using Snowflake. This will help you to ensure that your data is secure and compliant.
- Monitor your Snowflake environment. It is important to monitor your Snowflake environment to ensure that it is performing optimally. You can use tools such as Snowflake Monitoring to monitor your environment and identify potential problems.
Check out more of our Snowflake work.




